The Squirrel Collection Database (#squirreldatabase) is a database of objects, photos, and videos containing squirrel imagery gifted to me primarily from 2007 to the present day. One entry, however, is dated from almost a decade earlier. When my grandmother died she bequeathed me a vintage 1970’s Chalkware squirrel-shaped coin bank. Little did I know then, that this tchotchke would be a harbinger of collaboration and the squirrels to come.

1970’s chalk ware coin bank squirrel, bequeathed to me by my grandmother when she died in 1998.
My artistic practise includes portraits of hybrid-human squirrels which I have self-coined Squirrealism. These artworks have inadvertently affected the general public’s desire to collaborate with me. Hundreds of squirrel tchotchkes and digital imagery (links, memes and news stories) have been sent to me by snail mail, email, and direct message (Facebook, Twitter, and Instagram). As part of my art practise, I am cataloguing these squirrel artifacts into a MySQL database using an open-source, user contributed installation profile by CollectionAccess. Read more below.
Additionally, after being gifted a squirrel artifact (or sometimes a fantastic digital meme), I photograph the item and post it to Instagram @carollyneyardley using the search words: #squirreldatabase
In future, the #squirreldatabase will be made publicly accessible through an online searchable database (imetasquirrel.com). The online collection will provide me (and others) access to the materials in one repository to define future research agendas, and disseminate how squirrels are portrayed in art history, literature, pop culture, advertising, and media.

Skull: Squirrel cranium with teeth intact. Gifted by Dr. Charles Low, Invertebrate Biologist Xmas 2012 at Vic and Kathryn’s house.
Project Backgrounder
My project began with deciding on the best open-source software that would fit my needs, which is to catalogue many physical objects in order to box them up for storage and still be able to access the images and text descriptions (and throw away yellow sticky notes). I tossed around the idea of entering the data into an .xlsx – Excel workbook or .numbers – Apple’s iWork office suite, but decided that I might lose some data or some may need to be re-inputted during import into an online software solution. Time-wise it made sense to enter the data directly into the chosen online software with existing category configurations.
Other considerations:
Software support, category config, data imports, exports, backups, and linking to my existing website at www.carollyne.com, plus ease of navigation interface for online visitors.
My desired object categories included:
- accession number
- item title
- quantity
- gifted (name) or purchased (cost)
- date of acquisition
- description, dimensions
- multiple photos

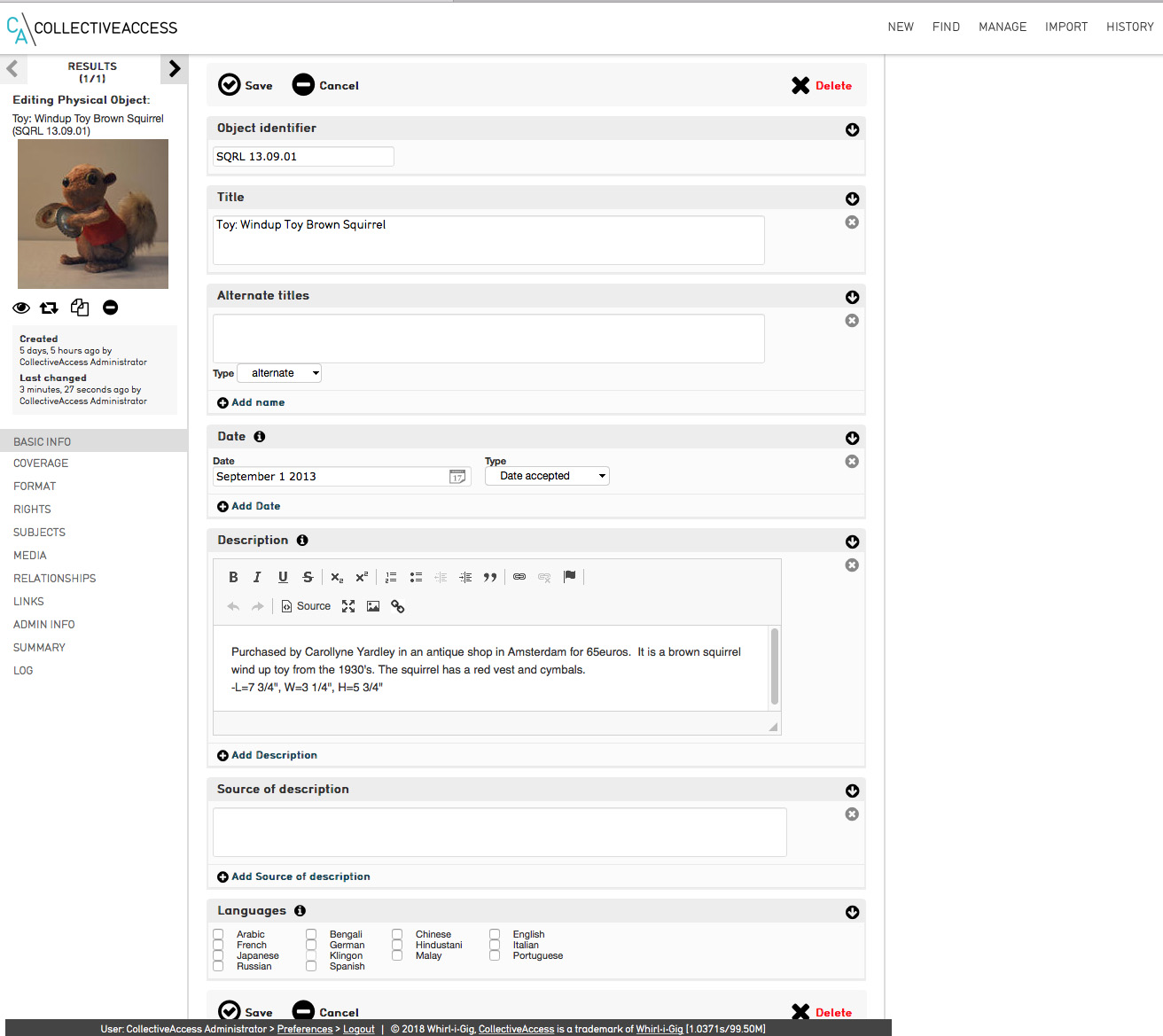
Toy: Windup Brown Squirrel. SQRL 13.09.01
Project Specifications
After some research, the software I selected for my project is by CollectiveAccess. This is free open-source software for managing and publishing museum and archival collections. It is a software for describing all kinds of things, and allows you to create catalogues that closely parallel your needs without custom programming.
CollectionAccess has a selection of user-contributed installation profiles, some of which are based on standard and some are completely custom.
The options for the installation wizard presented the following choices:
EBUCORE V1.4 2013
[DEFAULT] Visual resources collection
[Standard] CDWA-Lite 1.1
[Standard] DarwinCore
[Standard] DublinCore [2014 Revision]
[Standard] ISAD(G) – General International Standard Archival Desciption
[Standard] PBCore v1.2 REVISED 2013
[Standard] SPECTRUM
[Testing] Profile for test cases
The configuration library I chose was listed as selection of user-contributed installation profiles under Institutional Archives and Special Collections.
New Museum of Contemporary Art, New York, NY, USA.
Metadata Standards: Dublin Core
Object Types: collections, datasets, events, images, interactive resources, moving images, physical objects, services, software, sounds, texts
If you are interested in further reading visit this page:
https://docs.collectiveaccess.org/wiki/Installation_profile
https://collectiveaccess.org/configuration
CollectiveAccess: Screen Shot 2018-10-08
Project Process
Installing the Collective Access on our Star Global server required a server update using newer Apache 2.4 and PHP 5.6.
Then there was an opportunity to install a profile, test it, and just delete it and start again if it didn’t work the way I intended. Knowing I wanted to store audio, video, and still photos or object data, the [Standard] DublinCore [2014 Revision] sounded like a good option.
By choosing an existing community contributed one, it meant there would most likely be a more standard way of naming things.
I also registered the domain name imetasquirrel.com in order for the online database to be stand alone, however, the plan is to forward the domain alias to this portfolio page at https://www.carollyne.com/portfolio/portfolio-squirrel-database/ which keeps all my project info at one central location.
Next up was data entry. This is a time consuming and often tedious task that requires entry of the category, title, photographs, physical description, and labelling the squirrel artifact with the corresponding accession number. The accession number is determined by the date it was purchased or gifted to me (SQRL YY/MM/DD). Receipt of the physical objects entailed labelling them with a yellow sticky note detailing the pertinent information. This is fortunate, because I now have a good amount of info on each artifact going back to 2007. Additionally, this project presented an opportunity to train someone in data entry, and I have found a wonderful person interested in learning new skills which I am training to help me archive the collection. During the first initial entries, we made a nice discovery – the software allows for multiple photos to identify the object.
The tools required include – a laptop with Internet access, software such as Photoshop and iPhoto, a camera, label maker, and measuring tape.
Future
Please stay tuned as we enter the data over the course of the next few months, and watch for text discussing the web interface selection choices I will need to make. Of course, stay tuned also for live launch date so you can peruse the The Squirrel Collection database for yourself at http://www.imetasquirrel.com
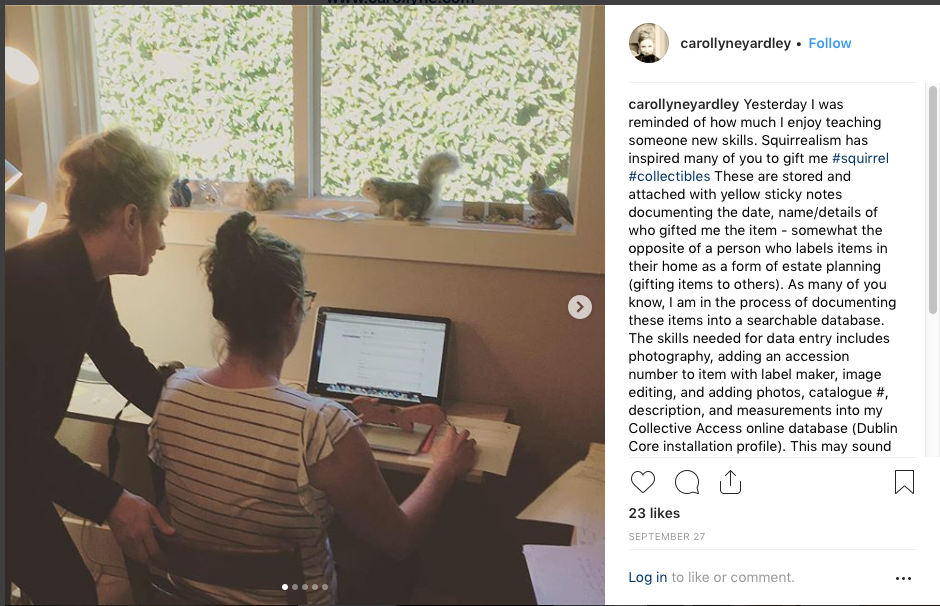
Database entry in progress.